
Robots.txt dosyası; Google, Bing, Yandex ve Yahoo gibi arama motoru botlarının söz konusu web sitesine olan erişimini kısıtlayabilir.
Bu yazımızda robots.txt dosyasının ne olduğundan neler yapabileceğine, nasıl oluşturulacağından doğru kullanımına kadar birçok noktayı ele alacağız.
Robots.txt dosyası hakkında bilgi edinmek, allow ve disallow komutlarını detaylı bir şekilde kullanmayı öğrenerek tarama bütçenizi daha verimli hâle getirmek için yazımızın devamını inceleyebilirsiniz.
Robots.txt Nedir?
Robots.txt dosyası; içerisinde allow ve disallow komutlarını barındıran, arama motoru botlarına verilen izinleri belirleyen bir metin dosyası türüdür.
Web sitelerinin Google bot gibi arama motoru botları tarafından verimli ve istenilen şekilde taranmasını sağlamak amacıyla oluşturulur.
Bu dosya; web sitesi sağlığı, SEO performansı, kullanıcı deneyimi ve web sayfalarıyla ilgili diğer teknik işlemler için kullanılır.
Robots.txt dosyasına sahip olmayan bir sitenin sayfaları istenilen şekilde taranamaz. Bu durum, web sitesinin arama motoru sonuç sayfasındaki görünürlüğünü direkt etkiler.
Çünkü robots.txt dosyasına sahip olmayan bir web sitesi, hangi sayfalarının taranacağına dair Google botlara komut veremez. Bu, söz konusu web sitesinin istenmeyen sayfalarının taranmasına ya da istenen sayfaların index alamamasına neden olur.
Robots.txt Dosyasının Önemi ve İşlevi
Robots.txt dosyası, bir web sitesinin en önemli bileşenlerinden biridir.
Genel hatlarıyla robots.txt dosyasının önemi; bir web sitesinin güvenlik, gizlilik ve performans gibi oldukça mühim noktaları için kritik işlevleri, şu şekilde sıralanabilir:
- İçerik Kontrolü ve Arama Motoru Botlarının Yönlendirilmesi: Metin dosyasına girilen belirli komutlar, arama motoru botlarının web sitesine bağlı bazı içeriklere erişememelerini sağlar. Böylece web sitesinin içeriği, SEO uzmanları tarafından kolaylıkla yönetilebilir.
- Index Performansının İyileştirilmesi: Robots.txt dosyası; login, sepet ve yönetici paneli gibi web sitesine bağlı olan fakat performans beklenmeyen sayfaların da indexlenmemesi yönünde botlara komutlar verebilir. Bu aksiyon yalnızca değerli sayfaların arama motoru botları tarafından indexlenmesinin istendiği durumlarda yapılır. Index performansının robots.txt dosyası aracılığıyla iyileştirilmesi, SEO çalışmalarının en önemli basamaklarından biridir.
- Gizlilik: Bazı web siteleri, kullanıcıların görmemesi ve gizli tutulması gereken web sayfalarına sahip olabilir. Bu sayfalarda genellikle hassas, özel ve gizli içerikler yer alır. Robots.txt dosyasına girilen belirli komutlarla bu tür sayfaların taranmaması ve kullanıcılara gösterilmemesi sağlanabilir.
- Tarama Bütçesinin Verimli Kullanımı: Robots.txt dosyasının en bilindik kullanım alanlarından olan tarama bütçesi yönetimi, web sitelerinin organik performansları için son derece önemlidir. Metin dosyasına girilen bazı komutlar, web sitesini taramaya gelen arama motoru botlarını yönlendirir. Bu durum, web sayfalarının tarama sıklığını direkt etkiler. Robots.txt dosyasında yapılan hatalar, botlar tarafından yapılan tarama isteklerinin verimsiz kullanılmasına yol açar.
- Site Haritasına Yönlendirme: Robots.txt dosyasına gelen arama motoru botları, burada bulunan komutları okuyarak verilen direktiflere göre hareket eder. Web sitelerinin tüm değerli sayfalarına ait adresleri içeren site haritasının URL’i, robots.txt dosyasına eklenebilir. Bu sayede botların sitemap’i kolayca bulması sağlanır.
- Indexlenmeyen Sayfaların Tespiti: Bazen SEO uzmanları, sitelerin bazı değerli sayfalarının index alamadığını tespit edebilir. Böyle durumlarda ilk kontrol edilmesi gereken yer, robots.txt dosyasıdır. Robots.txt dosyasında yapılacak bazı değişiklikler, değerli sayfaların index almaması sorununu çözebilir.
- SEO Performansının İyileştirilmesi: Robots.txt dosyası, SEO çalışmalarından alınacak performansın iyileştirilmesi için de sıklıkla kullanılır. Bu ortamda bulunan komutların düzenli ve planlı kontrolü, SEO çalışmalarının daha etkili sonuçlar vermesini sağlayacaktır.
Robots.txt Dosyası Oluşturma: İlk Adımlar
Robots.txt dosyası oluşturmak için atılması gereken ilk adım; Notepad, Visual Studio Code ya da TextEdit gibi bir metin editörünün seçilmesidir. Hangi metin editörünün tercih edildiğinin herhangi bir önemi yoktur.
Ardından tercih edilen text editör açılmalı ve robots.txt dosyasında yer alması gereken komut ve satırlar, ilgili yerlere eklenmelidir.
Bu noktada text editörle oluşturulan dosyanın UTF-8 kodlamasıyla kaydedildiğinden emin olunması gerekir. Aksi hâlde arama motoru botları, ilgili dosyayı görmezden gelebilir.
Robots.txt dosyası oluştururken dikkat edilmesi gereken bir diğer nokta, dosyanın isimlendirmesinin robots.txt olmasıdır. Farklı isimlendirmeler, birtakım sorunların ortaya çıkmasına yol açabilir.
Bir web sitesi yalnızca bir adet robots.txt metin dosyasına sahip olabilir. Bu nedenle ilgili dokümanın dikkatli bir şekilde doldurulması ve doğruluğundan emin olunduktan sonra yayınlanması gerekir.
Dosyanın kaydedilmesinin ardından yayınlama aşaması gelir. Robots.txt dosyası, web sitelerinin kök dizininde yer almalıdır. Bu ortam, diğer dosyaların da olduğu ana dizindir.
- Örneğin web sitemizin https://www.example.com olduğunu düşünelim.
- Bu örnekte, robots.txt dosyasının https://www.example.com/robots.txt konumunda bulunması gerekir.
- Robots.txt dosyasının https://www.example.com/sayfalar/robots.txt gibi bir adreste konumlandırılamayacağı unutulmamalıdır.
- https://www.example.com adresi için hazırlanan https://www.example.com/robots.txt adresi, yalnızca https://www.example.com için geçerlidir. https://www.blog.example.com ya da http://www.example.com gibi adresler için geçerli değildir.
Robots.txt Dosyasının Temel Yapısı ve Söz Dizimi
Robots.txt dosyası, belirli yapı ve söz dizimleri barındırır.
Bunlar şu şekilde sıralanabilir:
- User – agent
- Allow
- Disallow
- Sitemap
Bu temel robots.txt dosyası elemanlarının her birinin farklı işlevleri vardır. Elemanlar, arama motoru botlarına belirli komutların verilebilmesini mümkün kılar.
Bir robots.txt dosyası, (her web sitesindeki kurallar değişiklik gösterse de) genel olarak Amazon web sitesinin robots.txt dosyasının bir kısmından aldığımız bu örnek gibi görünür:
User-agent: *
Disallow: /exec/obidos/account-access-login
Disallow: /exec/obidos/change-style
Disallow: /exec/obidos/flex-sign-in
Allow: /gp/offer-listing/B000
Allow: /gp/offer-listing/9000
Disallow: /hp/video/profiles
Örnekten de anlaşılacağı üzere bir robots.txt dosyası genellikle user – agent: * ifadesiyle başlar. Allow ve disallow komutlarıyla devam eden dosya, genellikle sitemap satırıyla son bulur.
Robots.txt Dosyası ile İlgili Anahtar Kavramlar
Robots.txt dosyasında user-agent, allow, disallow ve sitemap gibi satırların buluğundan bahsetmiştik. Yazımızın bu bölümünde bu satırlarda yer alan ifadelerin ne anlama geldiğinden ve ne şekilde kullanılabileceklerinden bahsedeceğiz.
User-Agent
Robots.txt dosyasının baş kısmındaki user-agent direktifi, dosyada bulunan komutların hangi arama motoru botlarına yönelik olduğunu ifade eder.
Bu ifadenin user-agent: * şeklinde sonuna yıldız eklenerek verilmesi, söz konusu komutların tüm arama motoru botları için geçerli olduğunu ifade eder.
Web sitesi yöneticileri, user-agent satırını birden fazla kullanarak arama motoru botlarının yanı sıra tüm web site crawlerlarına farklı komutlar verebilirler.
Bunu bir örnekle açıklayalım:
- Web sitemizin Eteo Spider, ChatGPT ve CCBot tarafından indexlenmesini istemediğimizi düşünelim.
- Bu senaryoda robots.txt user-agent girdileri şu şekilde olmalıdır:
User-agent: EtaoSpider
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /
Aynı zamanda user-agent komutu, web sitesinin Google botları tarafından taranmasını engellemek için aşağıdaki gibi de kullanılabilir:
User-agent: Googlebot
Disallow: /
Web sitesinin Adsbot tarayıcılarını engellemek içinse aşağıdaki komut kullanılır:
User-agent: AdsBot-Google
Disallow: /
Disallow
Disallow, botlara spesifik olarak belirlenen URL’lerin taranmaması yönünde komutlar verir ve robots.txt dosyasının en önemli bileşenlerinden biridir.
Bu komut genellikle / ya da * ifadesiyle birlikte kullanılır.
Eğik çizgi ifadesi, kök dizindeki belirli bir uzantı dizininin indexlenmemesini söyler.
Örneğin Disallow : /ozel-sayfa/ komutu, arama motorunun web sitesinin kök dizinindeki /ozel-sayfa/ dizinine erişimini engeller.
Yıldız (*) ifadesiyse genellikle URL yapısının herhangi bir yerinde geçen ilgili uzantıların taranmasına engel olabilmek için kullanılır.
Mesela Disallow : /resimler/* komutu, /resimler/ dizinindeki tüm dosyaları ve alt dizinleri ifade eder.
Robots.txt dosyasında yer alan disallow komutu hatalı girilirse ilgili web sayfalarının arama motorları tarafından görmezden gelinmesine neden olabilir. Yani web sayfaları arama sonuçlarında kullanıcıların karşısına çıkamayabilir
Bu nedenle robots.txt dosyasına eklenen disallow komutlarının dosya yayınlanmadan önce kontrol edilmesi gerekir.
Allow
Allow komutu ise disallow komutunun tam tersi şekilde işler. Genellikle disallow aracılığıyla verilen kuralların bir anlamda sınırlandırılmasına yarar.
Bunu bir örnekle açıklayalım:
User- agent: *
Disallow: /ozel/
Allow: /ozel/sayfa2.html
- Bu örnekle robots.txt dosyasında arama motoru botlarına verilen komut, /ozel/ dizin dosyasını indexlememeleri yönündedir.
- Fakat bu dosyaya bağlı /ozel/sayfa2.html dizin dosyasının indexlenmesi istenir.
- Bu sayede /ozel/ dizininde olmasına rağmen /ozel/sayfa2.html dizini, disallow kuralından hariç tutulmuştur.
Eğeri allow komutu söz konusu robots.txt dosyasında yer almasaydı indexlenmesi istenen /ozel/sayfa2.html sayfasının taranmamasına neden olacaktı.
Sitemap
Robots.txt dosyasında yer alan site haritası satırı, metin dosyasını taramak için gelen arama motoru botlarına direkt web sitesinin sitemap adresini verir.
Böylece botlar, site haritasını taramak için kolay hareket edebilir ve sitenin istenen sayfalarını indexleyebilir.
Bu yöntem, SEO uzmanları tarafından sıklıkla kullanılır ve kullanılmalıdır.
Bu kısım şu şekilde gösterilir:
User-agent: *
Disallow:
Sitemap: http://www.ornekwebsitesi.com/sitemap.xml
Sitemap ile ilgili detaylı bilgi için “Sitemap Nedir? Nasıl Oluşturulur?” adlı yazımızı inceleyebilirsiniz.
Örnek Robots.txt Dosyası
Bir robots.txt metin dosyasında olması gereken elemanlardan söz ettik.
Tüm önemli elemanları içeren bir robots.txt dosyası örneği verelim:
User-agent: *
Disallow: /ozel/
Disallow: /ornek/sayfa/
Disallow: /admin-sayfası/
User-agent: Googlebot
Allow: /ozel/sayfa2.html
Sitemap: http://www.ornekwebsitesi.com/sitemap.xml
Arama Motoru Optimizasyonu ve Robots.txt
Robots.txt dosyası, SEO çalışmalarının opus magmum’udur.
Web sitesinin gereksiz sayfalarının arama motoru botlarına tarattırılmaması, sitenin sağlıklı olması için gereken bir eylemdir.
Sitenin sağlıklı bir yaşam sürmesi ve sürekli büyümesi ise SEO uzmanlarının en büyük isteklerindendir.
Bu sebeple robots.txt dosyası ve SEO arasında sıkı sıkıya bir ilişki vardır.
Bu ilişki, bir örnek üzerinden açıklanabilir:
- Web sitesinin değersiz ve istenmeyen sayfalarının disallow komutlarıyla not-indexed hâle getirilmesi, direkt bu hamle aracılığıyla gerçekleştirilir.
- Bunun için web sitesi sayfalarının URL’lerine ihtiyaç vardır.
- Google Search Console bu noktada devreye girer.
- Söz konusu araçla web sitesinin robots.txt dosyası üzerinden girilmesi gereken disallow uzantılarına kolaylıkla ulaşılabilir.
Robots.txt Dosyasıyla İlgili Yapılan Yaygın Hatalar ve Kaçınılması Gerekenler
Robots.txt dosyası bir web sitesine bağlı tüm sayfaların index durumunu direkt etkileyeceğinden bu ortamda hatalardan kaçınmak gerekir.
Robots.txt dosyasıyla ilgili yapılan yaygın hatalardan bazıları şöyle sıralanabilir:
- Tüm Web Sayfalarının Engellenmesi: Yanlış robots.txt disallow komutları, web sitesine bağlı tüm sayfaların engellenmesine neden olabilir. Bu durum, genellikle Disallow: / şeklindeki ifadelerden kaynaklanır.
- Sayfa Adlarının Yanlış Verilmesi: Robots.txt dosyası üzerinden engellenmek istenen web sayfalarının URL uzantıları doğru girilmelidir. Aksi hâlde değersiz sayfaların not-indexed statüsüne getirilmesi mümkün olmaz.
- Format Hataları: Robots.txt dosyasındaki allow, disallow ve user-agent gibi komutların kurala uygun girilmesi oldukça önemlidir. Örneğin /ozel disallow komutu yalnızca söz konusu dizini engellerken /ozel/ disallow komutu hem /ozel, hem bu dizine bağlı alt dizinleri etkileyecektir. Aynı şekilde allow komutlarının da hatalı girilmesi, taranması istenen web sayfalarının engellenmesine neden olacaktır.
- Robots.txt Dosyasının Güncellenmemesi: Robots.txt dosyasında yer alan komutlar, web sitelerinin URL yapılarına uygun şekilde oluşturulur. Fakat zaman içerisinde bu URL yapıları değişiklik gösterebilir ya da birtakım altyapı sorunları nedeniyle istenmeyen URL’ler ortaya çıkabilir. Bu sebeple robots.txt dosyasının belirli aralıklarla incelenmesi ve gerekli güncellemelerin gerçekleştirilmesi gerekir.
Bu hataların önüne geçebilmek için robots.txt dosyasını ziyaret eden arama motoru botlarının hareketleri, Google Search Console aracılığıyla incelenmelidir.
Google Search Console Aracılığıyla Robots.txt Kontrolü
Google Search Console, robots.txt dosyasıyla arama motoru botlarına verilen komutların istenen şekilde çalışıp çalışmadığını kontrol edebilmemize yarar.
Aşağıdaki adımları takip ederek Google Search Console üzerinden index sorunlarınızı nasıl inceleyebileceğinizi keşfedebilir, robots.txt dokümanınızı daha profesyonel şekilde güncelleyebilirsiniz:
- Google Search Console hesabınızı açın ve sol üstten mülkünüzü seçin.
- Sol menüde yer alan “Dizin Oluşturma” bölümünün altındaki “Sayfa Sayısı”nı seçin.
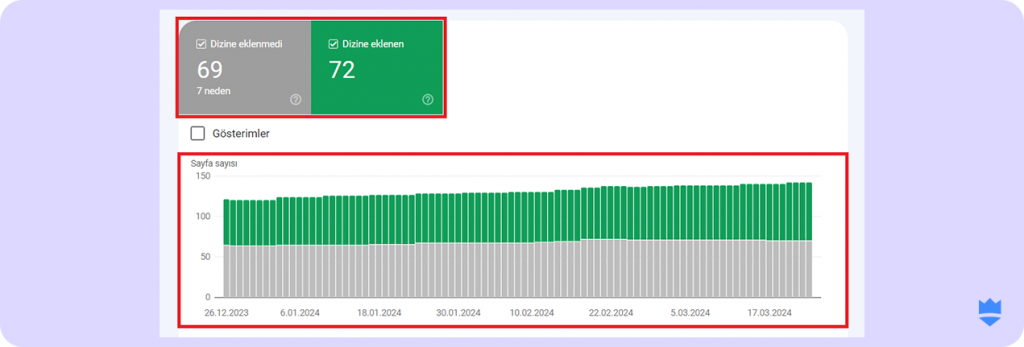
- Karşınıza çıkan ekran, indexlenen ve indexlenmeyen sayfalarınızı gösterir. Bu bölümden kaç adet sayfanızın indexed, kaçının not-indexed durumda olduğunu görüntüleyebilirsiniz.
- Sayfayı aşağı kaydırınca “Sayfalar neden dizine eklenmiyor?” alanıyla karşılaşacaksınız. Burada indexlenmeyen sayfalarınızın hangi nedenlerle arama motoru botları tarafından görmezden gelindiğini görüntüleyebilirsiniz.
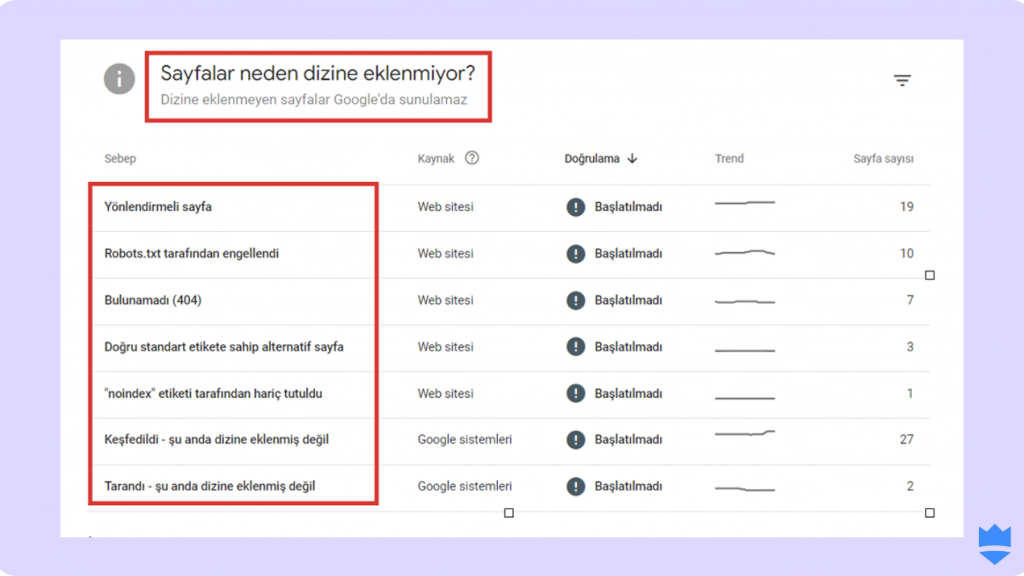
- Robots.txt dosyası aracılığıyla hangi sayfaların indexlenmediğini görmek içinse “Robots.txt tarafından engellendi” kısmına tıklamanız gerekir.
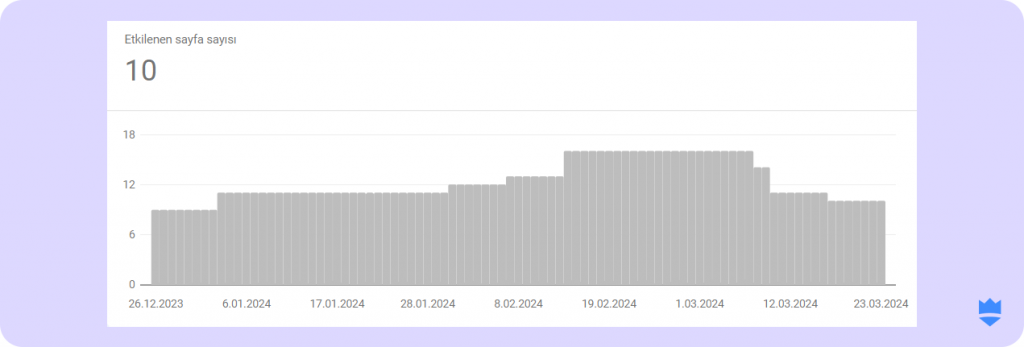
- Burada yer alan URL’leri inceleyebilir ve eğer gerekliyse disallow komutlarınızı güncelleyebilirsiniz.
Bu adımları izlemenin yanı sıra yine Google Search Console’da bulunan “URL Denetimi” bölümünü kullanarak da web sayfalarınızın indexlenip indexlenmediğini kontrol edebilirsiniz.
Bunun için:
- Google Search Console hesabınıza giriş yapın ve istediğiniz mülkü seçin.
- Ardından sol menüde bulunan “URL Denetimi”ne tıklayın. Bunun yerine sayfanın en üstünde yer alan arama kısmına da tıklayabilirsiniz.
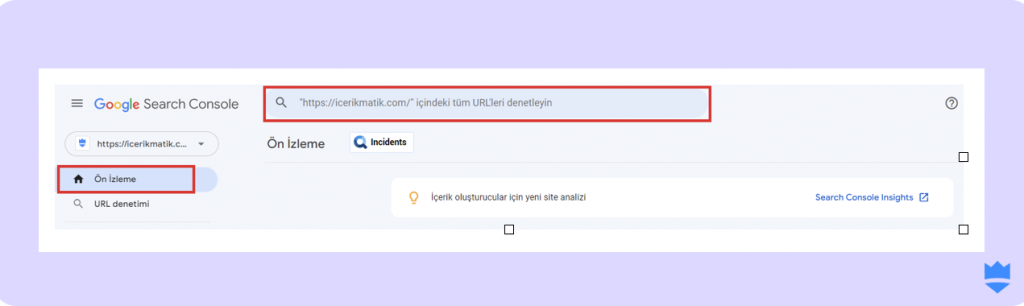
- Bu kısma indexlenip indexlenmediğini merak ettiğiniz URL’i girin ve işlemi onaylayın.
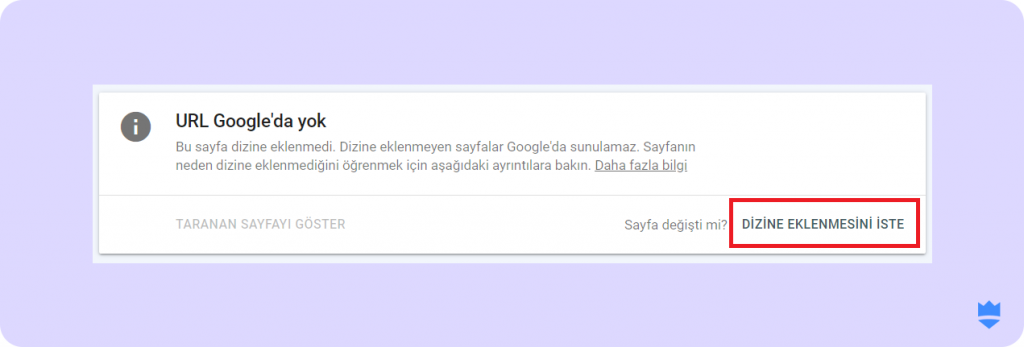
- Eğer söz konusu URL indexlenmiyorsa aşağıdaki uyarıyla karşılaşacaksınız:
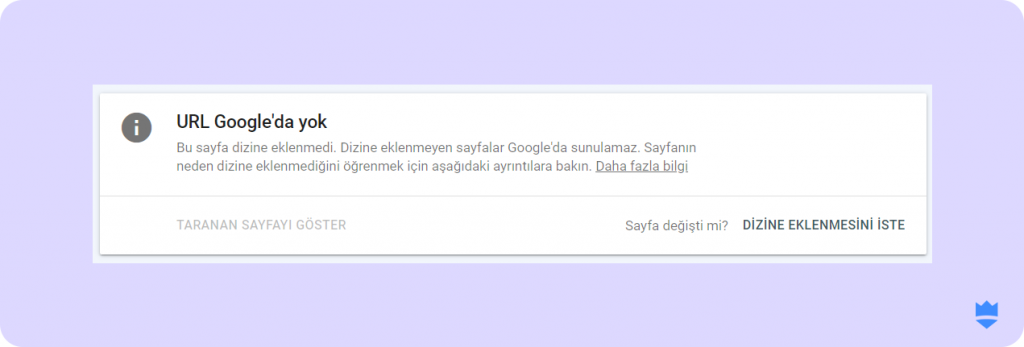
- Sayfayı aşağı kaydırarak sayfanızın neden indexlenmediğini de inceleyebilirsiniz.
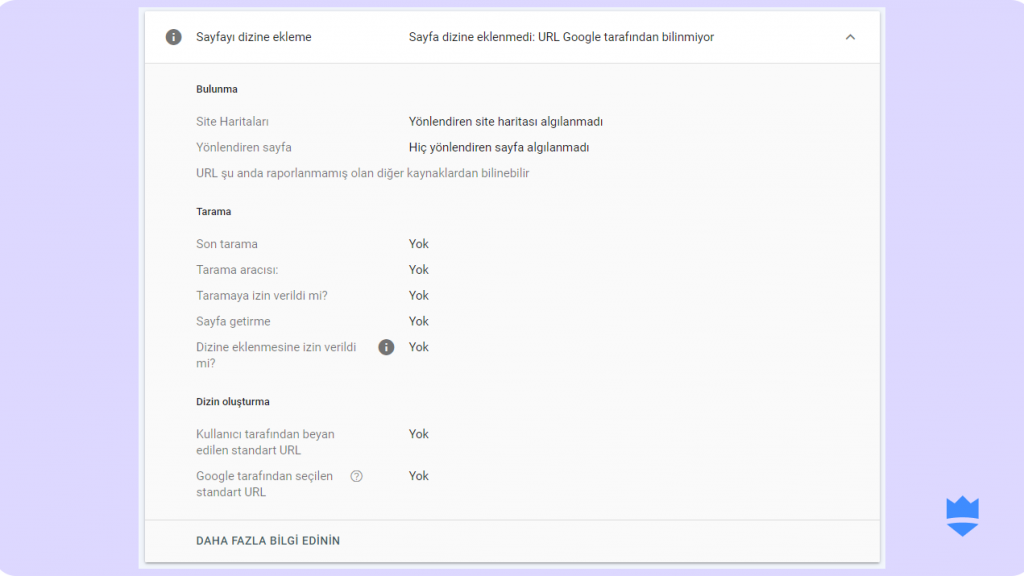
- Bu noktada ilgili sayfanın indexlenmesini istiyorsanız gerekli robots.txt (ya da diğer) işlemleri uygulamanızın ardından “Dizine Eklenmesini İste” butonuna tıklayabilirsiniz.
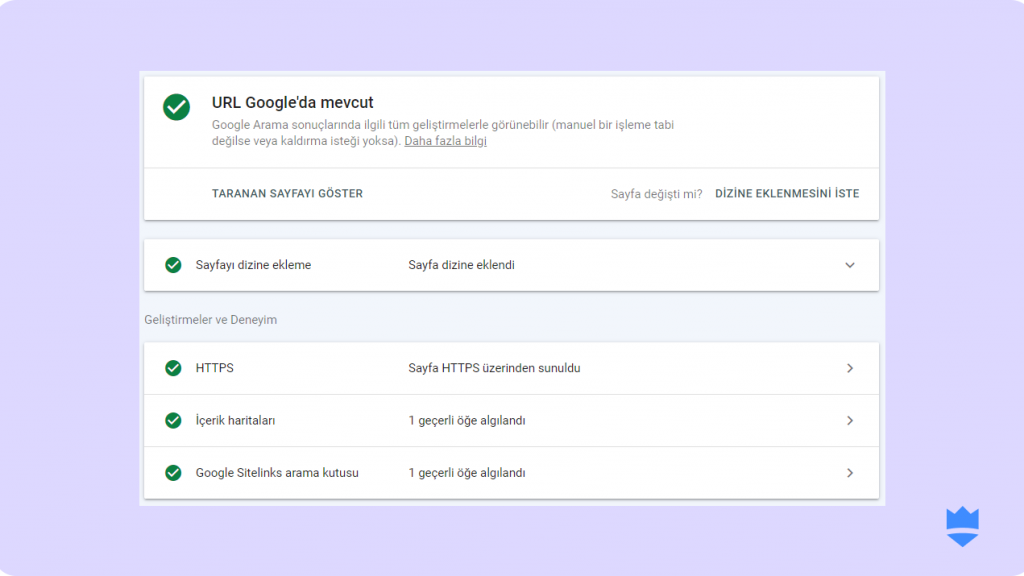
- Eğer sayfanız Google botlar tarafından indexlenmişse aşağıdaki görüntüyle karşılaşacaksınız:
Sonuç
Robots.txt dosyası aracılığıyla arama motoru botlarının söz konusu web sitesinin hangi sayfalarını tarayıp taramayacağını belirlemek mümkündür.
Robots.txt müdahalelerini planlı ve kontrollü gerçekleştirmeyen web siteleri, istenilen performansı gösteremez.
Siz de robots.txt dosyası ve komutları hakkında paylaştığımız bilgileri uygulamaya geçebilir, böylece web sitenizin istediğiniz şekilde taranmasını sağlayabilirsiniz.
Tarama kaynakları optimize edildiğinde bu durumun web sitenizin arama motoru sonuç sayfalarındaki görünürlüğünü doğrudan etkileyeceğini unutmayın!



